This is a continuation of our series of blogs about deployment of MAS on Bare Metal or on-premise scenarios. In this case, we are going to describe how to configure the Image Registry in the RedHat OpenShift Cluster, so it is backed up by persistent Shared Storage. Notice that Cloud Deployments will typically have the Cluster Image Registry already configured using one of the Storage options that is provided by the Cloud Provider. However, for Bare Metal scenarios, including SNO, such provisioning is not configured by default.
One of the main considerations of our approaches is to try to make our deployments as self-contained as possible and avoid spawning external dependencies and reuse a Shared File Level Storage Class that should be already provisioned for our cluster (see our previous Blog entries on “How to create and use a local Storage Class for SNO” for an example).
The IBM documentation around this can be found currently at Enabling the OpenShift internal image registry - IBM Documentation, and it proposes using either an OpenShift Data Foundation deployment (which will not exist for an SNO) or otherwise an externally configured NFS server in the Bastion Host which is not a very good architectural approach as it creates a single point of failure plus performance may not be that good. We could use an externally provisioned NFS server when that is provided by a Cloud Provider even in Bare Metal scenarios (such as an IBM File Storage for Classic or IBM File Storage for VPC) which should be highly available and have good performance. However, for on-premise installs the option does not typically exist.
To confirm the Image Registry is not provisioned with persistent storage, we can use the following “oc” command:
oc get configs.imageregistry.operator.openshift.io/cluster -o jsonpath='{.spec.managementState}'
And it should return the Management State of the Image Registry, in our case, it should be “Removed”. If for some reason it states otherwise (such as “Managed”) then no further steps may be required. If the Image Registry is already configured as “Managed” then confirming its status is OK, will be a recommended additional step as discussed at the end of this blog entry.
For this, we are going to provision a Persistent Volume Claim first, then attach it to the Image Registry operator and do a few more changes afterwards.
Sizing the PVC is an important consideration and given the use of the Internal Image Registry for storing the Build Images for the “maxinst” (called “admin”) and each of the MAS Manage bundles (such as “all” or “ui”, “cron”, “mif”, etc.), we should be able to estimate the approximate size required plus a safety margin. IBM states and recommend using 500GB as the size which may be too much for small deployments or not enough for multi MAS Core instances with multiple Manage bundles.
Therefore, we recommend sizing the required Storage to be 2 times the size of each of the images (to allow for deferred cleanup of older unused images that may exist on the Image Registry simultaneously with newer images for a while). In our experience, each image takes about 25 to 30 GB of space. The bare minimum of space for a single Manage instance should be 2 * 2 * 30 = 120 GB. The formula we are using is <factor> * <number of images> * 30 in GB. The <factor> we selected above is 2, the <number of images> is also 2 for a single MAS Manage instance of type “all” (which will be one “admin” and one “all” image). The number will be greater if splitting the “all” bundle into specialized “ui”, “mif”, “cron”, etc. bundles and we should count each once to make up the correct <number of images>.
Before starting the actual configurations, we should gather some information first, in our case:
- The Storage Class to use for the PVC. As per variable “IMAGE_REGISTRY_STORAGE_CLASS” below.
- The Access Mode for the Storage Class (in the case of our SNO deployments that use the LVM Storage solution as per the previous posts, then the Access Mode should be “ReadWriteOnce” and, when using the ODF/OCS Class “ocs-storagecluster-cephfs” it should be “ReadWriteMany”). As per variable “STORAGE_ACCESS_MODE” below. NFS based Storage should also use “ReadWriteMany”.
- The Size as per above. As per variable “IMAGE_REGISTRY_STORAGE_SIZE” below.
- The Number of Replicas. For SNO, it is best to configure a single replica to minimize resource usage. For highly available, multi node configurations probably using ODF/OCS, then it should be up to 3 replicas, depending on the number of Worker Nodes. This is also related to the Access Mode, as if we use “ReadWriteOnce” then the recommendation is to use a single Replica. As per variable “IMAGE_REGISTRY_NUMBER_OF_REPLICAS” below.
- The PVC Name. This can be any valid name, but we tend to use “image-registry-storage”. As per variable “IMAGE_REGISTRY_PVC_NAME” below.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
annotations:
imageregistry.openshift.io: 'true'
name: ${IMAGE_REGISTRY_PVC_NAME}
namespace: openshift-image-registry
spec:
accessModes:
- ${STORAGE_ACCESS_MODE}
resources:
requests:
storage: ${IMAGE_REGISTRY_STORAGE_SIZE}
storageClassName: ${IMAGE_REGISTRY_STORAGE_CLASS}
The intention is to replace the variables with proper values, as referenced above. One example is being presented below:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: image-registry-storage
namespace: openshift-image-registry
annotations:
imageregistry.openshift.io: 'true'
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 500Gi
storageClassName: ocs-storagecluster-cephfs
Once submitted, if the Storage Class has Automatic Provisioning, as all the classes we are configuring for our deployments and the Storage Class has a “volumeBindingMode” of “Immediate” instead of “WaitForFirstConsumer” then we should see a Persistent Volume created for it and Bound to the Persistent Volume Claim automatically. Otherwise, and if no Automatic Provisioning is available for the Storage Class, then manual creation of a Persistent Volume first may be needed and the manually provisioned PV will be also referenced from the PVC; see the IBM page referenced in the link above for details on how to create a Persistent Volume (in their case, for a NFS mount).
Assuming we have the Persistent Volume Claim provisioned and bound, it should look like below in the OpenShift Console:

Next, we are going to patch the Image Registry Operator to use the provisioned Persistent Volume Claim, using the following “oc” command:
oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"storage":{"pvc":{"claim":"${IMAGE_REGISTRY_PVC_NAME}"}}}}' --type=merge
Replacing the variable “IMAGE_REGISTRY_PVC_NAME” with the correct value.
After that, we are going to configure the intended Number of Replicas, also using an “oc” command:
oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"rolloutStrategy":"Recreate","replicas":${IMAGE_REGISTRY_NUMBER_OF_REPLICAS}}}' --type=merge
Replace the variable “IMAGE_REGISTRY_NUMBER_OF_REPLICAS” with the correct value.
Next, we are going to configure the Image Registry to be “Managed” (from the previous value that should be “Removed” as per above discussion), by using the command:
oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"managementState":"Managed"}}' --type=merge
Finally, we are going to define an External Route to the Image Registry, to do so, we used the following “oc” command:
oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=merge
This last command will cause the Red Hat OpenShift Cluster to go into a state of reconciliation and may be unavailable for a while until everything comes back again.
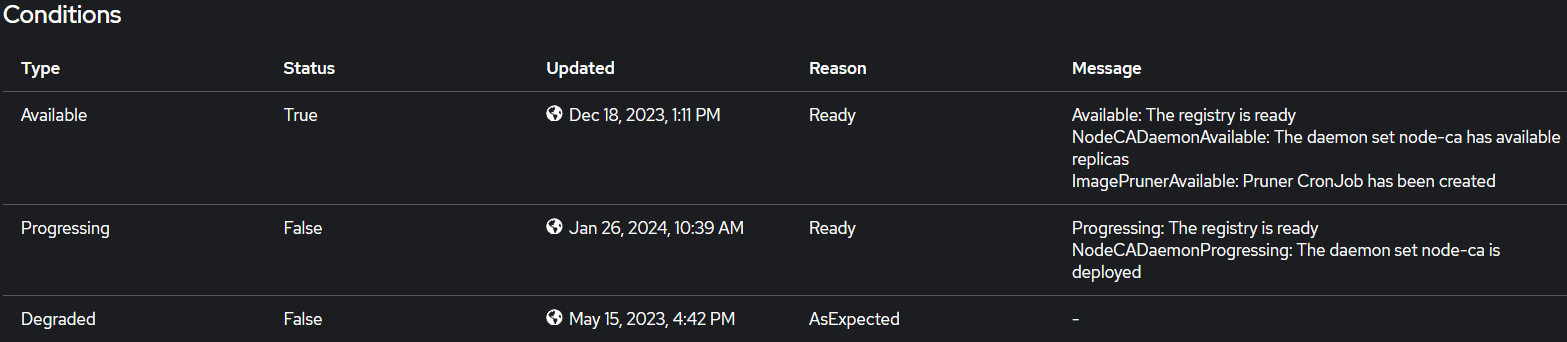
To confirm everything went well and that the Image Registry is now usable, we could either use an “oc” command or the OpenShift Console. Both methods are being presented below.
To use an “oc” command, submit the following:
oc get co image-registry -o jsonpath='{.status.conditions[?(@.type=="Available")].message}'
And it should return a response stating:
Available: The registry is ready
NodeCADaemonAvailable: The daemon set node-ca has available replicas
ImagePrunerAvailable: Pruner CronJob has been created
We could also check using the OpenShift Console, to do so, go to Administration -> Cluster Settings -> Cluster Operators and then from the list, locate and select the Image Registry Cluster Operator, then on its details page, it should look under Conditions like the below screenshot: